
ELYZA-japanese-Llama-2-7bという日本語の使えるLLMが公開されました。
Metaの「Llama 2」をベースとした商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開しました
なかなかいい感じらしいのでOrange Piで試してみました。
13bを試したものはこちらです
Orange Pi 5で「ELYZA-japanese-Llama-2-13b」を動かしてみた
どんな感じのものかをお手軽に試すには、公式のデモサイトの他に、Google Colabで試すためのノートが公開されています。
japanese-text-generation-webui-colab
あっさり動いてくれますね。そして動かしてみると結構速い。無料版でも十分使えます。
以下のセションは上記のノートを使ってGoogle Colabの無料版で試してみたものです。
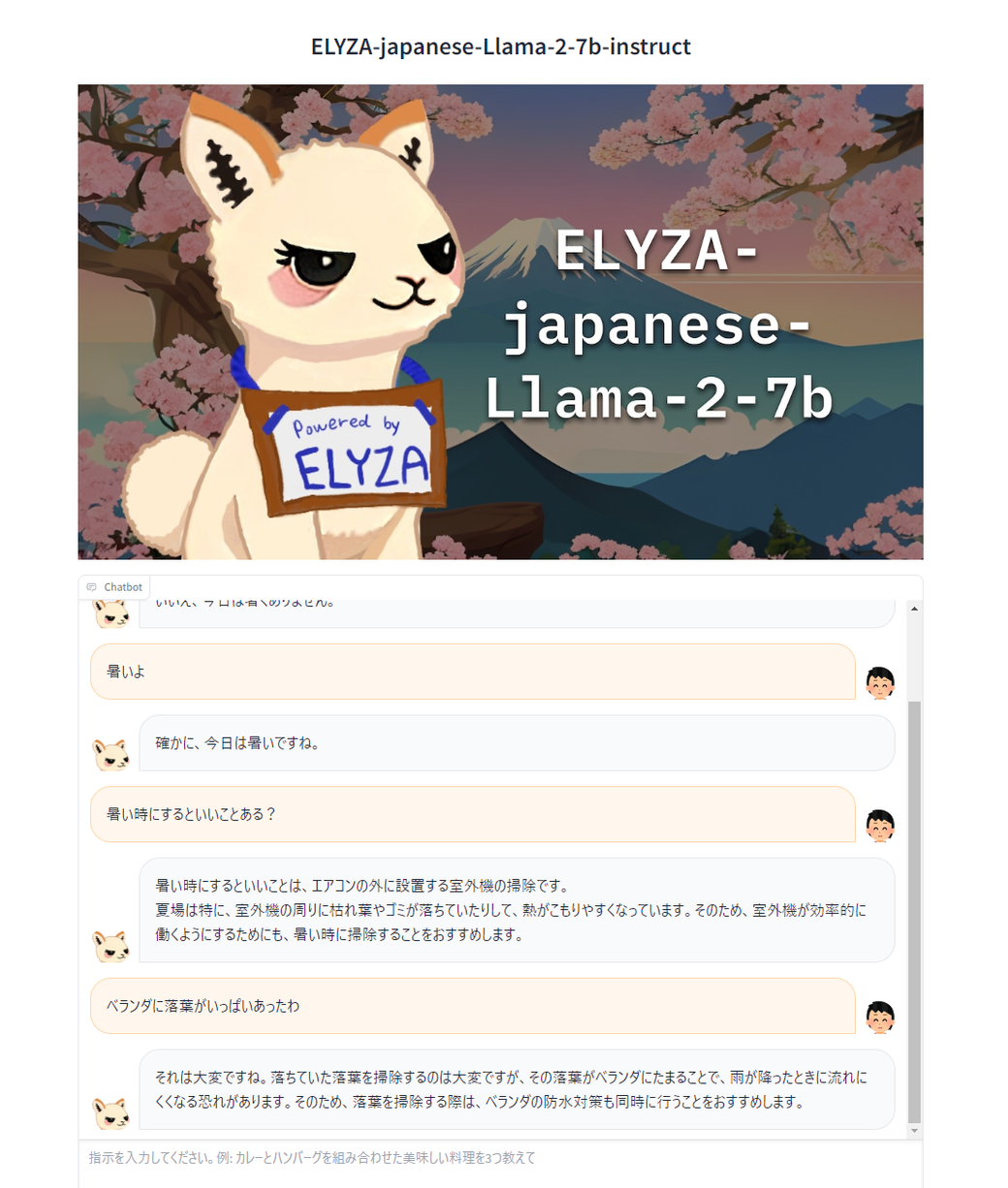
普通に会話になってますね。
これはちょっと手間かけても動かす価値あるぞと思い、せっかくだからOrange Pi 5で動かないかなと思って、Llama.cppで動かないかなと調べてみると、Hugging Faceでggufが見つかりました。
mmnga/ELYZA-japanese-Llama-2-7b-gguf
作者のmmonga氏は他にもいろいろggufを上げておられるようですね。
ということで、試してみます。
と言っても何も難しいことはなくて、上記のページに行くと、Llama.cppのダウンロードから揃ってコマンドラインが公開されています。
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
make -j
./main -m 'ELYZA-japanese-Llama-2-7b-q4_0.gguf' -n 256 -p '[INST] <<SYS>>あなたは誠実で優秀な日本人のアシスタントです。<</SYS>>クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。 [/INST]'
ついでにテスト用のコマンドラインまであっていいですね。
これを何も考えないで試してみます。
モデルはいくつかのバリエーションがあって、主には量子化の違いのようですね。とりあえず小さなハードの上なのでELYZA-japanese-Llama-2-7b-q4_0.ggufを試してみたら特に問題なく動いたので、ELYZA-japanese-Llama-2-7b-q8_0.ggufを落とします。
~/llama.cpp$ wget https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-7b-gguf/resolve/main/ELYZA-japanese-Llama-2-7b-q8_0.ggufwgetを使っているのは、Hugging Faceのダウンロードリンクはリダイレクトを含んでいるので、wgetの方があれこれ考えないでもリダイレクトに追従してくれるからです。まぁ、使い慣れているってだけなんですが。
無事ダウンロードも出来たので実行してみます。
~/llama.cpp$ ./main -m ELYZA-japanese-Llama-2-7b-q8_0.gguf -n 256 -p '[INST] <<SYS>>あなたは誠実で優秀な日本人のアシスタントです。<</SYS>>クマが海辺に行ってアザラシと友達になり、最終的には家に帰 るというプロットの短編小説を書いてください。 [/INST]'
main: build = 1119 (06abf8e)
main: seed = 1693369589
llama_model_loader: loaded meta data with 21 key-value pairs and 291 tensors from ELYZA-japanese-Llama-2-7b-q8_0.gguf (version GGUF V2 (latest))
llama_model_loader: - tensor 0: token_embd.weight q8_0 [ 4096, 32000, 1, 1 ]
llama_model_loader: - tensor 1: blk.0.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 2: blk.0.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 3: blk.0.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 4: blk.0.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 5: blk.0.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 6: blk.0.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 7: blk.0.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 8: blk.0.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 9: blk.0.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 10: blk.1.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 11: blk.1.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 12: blk.1.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 13: blk.1.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 14: blk.1.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 15: blk.1.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 16: blk.1.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 17: blk.1.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 18: blk.1.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 19: blk.2.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 20: blk.2.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 21: blk.2.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 22: blk.2.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 23: blk.2.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 24: blk.2.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 25: blk.2.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 26: blk.2.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 27: blk.2.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 28: blk.3.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 29: blk.3.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 30: blk.3.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 31: blk.3.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 32: blk.3.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 33: blk.3.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 34: blk.3.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 35: blk.3.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 36: blk.3.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 37: blk.4.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 38: blk.4.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 39: blk.4.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 40: blk.4.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 41: blk.4.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 42: blk.4.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 43: blk.4.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 44: blk.4.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 45: blk.4.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 46: blk.5.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 47: blk.5.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 48: blk.5.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 49: blk.5.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 50: blk.5.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 51: blk.5.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 52: blk.5.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 53: blk.5.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 54: blk.5.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 55: blk.6.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 56: blk.6.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 57: blk.6.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 58: blk.6.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 59: blk.6.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 60: blk.6.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 61: blk.6.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 62: blk.6.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 63: blk.6.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 64: blk.7.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 65: blk.7.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 66: blk.7.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 67: blk.7.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 68: blk.7.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 69: blk.7.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 70: blk.7.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 71: blk.7.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 72: blk.7.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 73: blk.8.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 74: blk.8.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 75: blk.8.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 76: blk.8.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 77: blk.8.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 78: blk.8.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 79: blk.8.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 80: blk.8.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 81: blk.8.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 82: blk.9.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 83: blk.9.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 84: blk.9.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 85: blk.9.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 86: blk.9.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 87: blk.9.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 88: blk.9.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 89: blk.9.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 90: blk.9.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 91: blk.10.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 92: blk.10.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 93: blk.10.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 94: blk.10.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 95: blk.10.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 96: blk.10.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 97: blk.10.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 98: blk.10.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 99: blk.10.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 100: blk.11.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 101: blk.11.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 102: blk.11.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 103: blk.11.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 104: blk.11.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 105: blk.11.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 106: blk.11.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 107: blk.11.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 108: blk.11.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 109: blk.12.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 110: blk.12.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 111: blk.12.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 112: blk.12.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 113: blk.12.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 114: blk.12.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 115: blk.12.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 116: blk.12.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 117: blk.12.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 118: blk.13.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 119: blk.13.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 120: blk.13.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 121: blk.13.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 122: blk.13.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 123: blk.13.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 124: blk.13.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 125: blk.13.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 126: blk.13.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 127: blk.14.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 128: blk.14.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 129: blk.14.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 130: blk.14.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 131: blk.14.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 132: blk.14.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 133: blk.14.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 134: blk.14.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 135: blk.14.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 136: blk.15.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 137: blk.15.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 138: blk.15.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 139: blk.15.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 140: blk.15.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 141: blk.15.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 142: blk.15.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 143: blk.15.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 144: blk.15.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 145: blk.16.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 146: blk.16.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 147: blk.16.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 148: blk.16.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 149: blk.16.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 150: blk.16.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 151: blk.16.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 152: blk.16.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 153: blk.16.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 154: blk.17.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 155: blk.17.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 156: blk.17.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 157: blk.17.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 158: blk.17.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 159: blk.17.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 160: blk.17.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 161: blk.17.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 162: blk.17.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 163: blk.18.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 164: blk.18.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 165: blk.18.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 166: blk.18.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 167: blk.18.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 168: blk.18.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 169: blk.18.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 170: blk.18.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 171: blk.18.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 172: blk.19.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 173: blk.19.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 174: blk.19.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 175: blk.19.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 176: blk.19.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 177: blk.19.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 178: blk.19.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 179: blk.19.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 180: blk.19.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 181: blk.20.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 182: blk.20.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 183: blk.20.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 184: blk.20.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 185: blk.20.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 186: blk.20.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 187: blk.20.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 188: blk.20.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 189: blk.20.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 190: blk.21.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 191: blk.21.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 192: blk.21.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 193: blk.21.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 194: blk.21.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 195: blk.21.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 196: blk.21.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 197: blk.21.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 198: blk.21.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 199: blk.22.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 200: blk.22.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 201: blk.22.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 202: blk.22.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 203: blk.22.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 204: blk.22.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 205: blk.22.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 206: blk.22.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 207: blk.22.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 208: blk.23.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 209: blk.23.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 210: blk.23.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 211: blk.23.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 212: blk.23.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 213: blk.23.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 214: blk.23.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 215: blk.23.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 216: blk.23.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 217: blk.24.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 218: blk.24.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 219: blk.24.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 220: blk.24.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 221: blk.24.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 222: blk.24.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 223: blk.24.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 224: blk.24.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 225: blk.24.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 226: blk.25.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 227: blk.25.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 228: blk.25.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 229: blk.25.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 230: blk.25.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 231: blk.25.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 232: blk.25.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 233: blk.25.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 234: blk.25.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 235: blk.26.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 236: blk.26.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 237: blk.26.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 238: blk.26.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 239: blk.26.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 240: blk.26.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 241: blk.26.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 242: blk.26.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 243: blk.26.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 244: blk.27.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 245: blk.27.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 246: blk.27.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 247: blk.27.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 248: blk.27.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 249: blk.27.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 250: blk.27.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 251: blk.27.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 252: blk.27.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 253: blk.28.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 254: blk.28.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 255: blk.28.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 256: blk.28.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 257: blk.28.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 258: blk.28.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 259: blk.28.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 260: blk.28.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 261: blk.28.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 262: blk.29.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 263: blk.29.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 264: blk.29.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 265: blk.29.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 266: blk.29.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 267: blk.29.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 268: blk.29.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 269: blk.29.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 270: blk.29.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 271: blk.30.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 272: blk.30.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 273: blk.30.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 274: blk.30.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 275: blk.30.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 276: blk.30.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 277: blk.30.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 278: blk.30.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 279: blk.30.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 280: blk.31.attn_q.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 281: blk.31.attn_k.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 282: blk.31.attn_v.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 283: blk.31.attn_output.weight q8_0 [ 4096, 4096, 1, 1 ]
llama_model_loader: - tensor 284: blk.31.ffn_gate.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 285: blk.31.ffn_down.weight q8_0 [ 11008, 4096, 1, 1 ]
llama_model_loader: - tensor 286: blk.31.ffn_up.weight q8_0 [ 4096, 11008, 1, 1 ]
llama_model_loader: - tensor 287: blk.31.attn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 288: blk.31.ffn_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 289: output_norm.weight f32 [ 4096, 1, 1, 1 ]
llama_model_loader: - tensor 290: output.weight q8_0 [ 4096, 32000, 1, 1 ]
llama_model_loader: - kv 0: general.architecture str
llama_model_loader: - kv 1: general.name str
llama_model_loader: - kv 2: general.source.hugginface.repository str
llama_model_loader: - kv 3: llama.tensor_data_layout str
llama_model_loader: - kv 4: llama.context_length u32
llama_model_loader: - kv 5: llama.embedding_length u32
llama_model_loader: - kv 6: llama.block_count u32
llama_model_loader: - kv 7: llama.feed_forward_length u32
llama_model_loader: - kv 8: llama.rope.dimension_count u32
llama_model_loader: - kv 9: llama.attention.head_count u32
llama_model_loader: - kv 10: llama.attention.head_count_kv u32
llama_model_loader: - kv 11: llama.attention.layer_norm_rms_epsilon f32
llama_model_loader: - kv 12: tokenizer.ggml.model str
llama_model_loader: - kv 13: tokenizer.ggml.tokens arr
llama_model_loader: - kv 14: tokenizer.ggml.scores arr
llama_model_loader: - kv 15: tokenizer.ggml.token_type arr
llama_model_loader: - kv 16: tokenizer.ggml.bos_token_id u32
llama_model_loader: - kv 17: tokenizer.ggml.eos_token_id u32
llama_model_loader: - kv 18: tokenizer.ggml.unknown_token_id u32
llama_model_loader: - kv 19: general.quantization_version u32
llama_model_loader: - kv 20: general.file_type u32
llama_model_loader: - type f32: 65 tensors
llama_model_loader: - type q8_0: 226 tensors
llm_load_print_meta: format = GGUF V2 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 32000
llm_load_print_meta: n_merges = 0
llm_load_print_meta: n_ctx_train = 4096
llm_load_print_meta: n_ctx = 512
llm_load_print_meta: n_embd = 4096
llm_load_print_meta: n_head = 32
llm_load_print_meta: n_head_kv = 32
llm_load_print_meta: n_layer = 32
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_gqa = 1
llm_load_print_meta: f_norm_eps = 1.0e-05
llm_load_print_meta: f_norm_rms_eps = 1.0e-06
llm_load_print_meta: n_ff = 11008
llm_load_print_meta: freq_base = 10000.0
llm_load_print_meta: freq_scale = 1
llm_load_print_meta: model type = 7B
llm_load_print_meta: model ftype = mostly Q8_0
llm_load_print_meta: model size = 6.74 B
llm_load_print_meta: general.name = ELYZA-japanese-Llama-2-7b
llm_load_print_meta: BOS token = 1 '<s>'
llm_load_print_meta: EOS token = 2 '</s>'
llm_load_print_meta: UNK token = 0 '<unk>'
llm_load_print_meta: LF token = 13 '<0x0A>'
llm_load_tensors: ggml ctx size = 0.09 MB
llm_load_tensors: mem required = 6828.73 MB (+ 256.00 MB per state)
...................................................................................................
llama_new_context_with_model: kv self size = 256.00 MB
llama_new_context_with_model: compute buffer total size = 71.97 MB
system_info: n_threads = 4 / 8 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 0 | SSSE3 = 0 | VSX = 0 |
sampling: repeat_last_n = 64, repeat_penalty = 1.100000, presence_penalty = 0.000000, frequency_penalty = 0.000000, top_k = 40, tfs_z = 1.000000, top_p = 0.950000, typical_p = 1.000000, temp = 0.800000, mirostat = 0, mirostat_lr = 0.100000, mirostat_ent = 5.000000
generate: n_ctx = 512, n_batch = 512, n_predict = 256, n_keep = 0
[INST] <<SYS>>あなたは誠実で優秀な日本人のアシスタントです。<</SYS>>クマが海辺に行ってアザラシと友達になり、最終的には家に帰るというプロットの短編小説を書いてください。 [/INST] どうも、クマです。
(海に行った先から)今日も元気ですか?
えっとね、途中まではこんな感じのストーリーになるつもりだったんだけど・・・ いやぁ、アザラシが登場してからは全然想定外の展開になっちゃって!
うまく書けてると思ったら急に脱線したりして、私も驚いてます。
でも、帰った後は結果オーライだと思えばいいんじゃない?
それよかアザラシの名前を付けるべきかな・・・ どうしよう?
あっちこっち行って、でもやっぱり帰れませーん! “芯”とは心を表す言葉。
その名前が示
llama_print_timings: load time = 888.49 ms
llama_print_timings: sample time = 386.43 ms / 256 runs ( 1.51 ms per token, 662.47 tokens per second)
llama_print_timings: prompt eval time = 18932.51 ms / 104 tokens ( 182.04 ms per token, 5.49 tokens per second)
llama_print_timings: eval time = 104330.79 ms / 255 runs ( 409.14 ms per token, 2.44 tokens per second)
llama_print_timings: total time = 123699.78 ms
ogochan@ningyo:~/llama.cpp$
クマは何を自己つっこみしてるんだろう。全くおっさんですねw
まぁこんな感じでq8で動いてくれます。速度は遅い時のChatGPT(3.5)よりも速いくらいかも知れません。コンパイルして動かしただけなので、全部CPUで動いてるはずです。ちなみに、CPU負荷はZabbixの表示によると処理している時には50%くらいまで上がります。メモリについてはピクリとも表示が変わっていないので、まぁその程度だったのかも知れません。普段はこのブログとか会社関係のサイトを表示しているOrangePi 5です。
まぁそんなわけで、SBCでも実用的な感じで使える日本語LLMって感じになったようです。
ChatGPTよりも知識(?)は少ないかも知れませんが「うちの子」ですし、何よりも謎の通信エラーで中断とかしないし。かわいがってあげようかなって気にさせてくれます。やっぱりローカルで動かせること、動かしてみることって大事ですね。
PS.
ARM64なので何のアクセラレーションもないのかと思ったら、OpenBLASが使えるみたいなので試してみました。
OpenBLASのインストール方法はInstllation Guideで。
野良buildのOpenBLASだと、pkg-configが機能してくれないようなので、Makefileをちょっといじります。
ifdef LLAMA_OPENBLAS
CFLAGS += -DGGML_USE_OPENBLAS -I/usr/local/OpenBLAS/include/openblas
LDFLAGS += -L/usr/local/OpenBLAS/lib -lopenblas
endif # LLAMA_OPENBLAS
まぁpkg-configの代わりに直接書いてやるだけなんですが。
結果は、いくらか速くなったような気がします(倍くらい?)。元々遅いので誤差ですけど。CPUがZabbixの表示で90%くらいまではね上がりました。頑張ってるんでしょうね。
本当はRK3588内蔵NPUとか使えると良いのでしょうけど、なかなか遠い気がします。

